CNN Architectures
Convolutional Neural Network Architectures
Introduction
We will now explore some famous CNN architectures as implemented in torchvision. This package adds functionality to the PyTorch ecosystem focused on working with images and video data. You have already seen applications of torchvision in the context of defining and applying transforms. This package also provides tools for loading images, defining image DataSets, and loading built-in datasets. As you will see in this section, it also provides access to famous CNN architectures and associated pre-trained weights. Other than just scene labeling or classification tasks, there are also tools and datasets specific to semantic segmentation, object detection, and instance segmentation.
In this section, we will specifically explore VGGNet and ResNet architectures. However, we will not discuss their implementations in detail since these models are discussed in-depth in the CNN lecture module. Instead, we will focus on how to implement these models using torchvision. The examples here for VGGNet and ResNet will translate well to other architectures made available through torchvision. In the next section, we will bring together what you have learned throughout the CNN modules to use transfer learning and a modified ResNet-34 architecture to classify the EuroSatAllBands dataset.
I begin by importing the needed packages. In this module, I will use the Python Imaging Library (PIL) to read in images. I am using this package because it works well with torchvision. I also set the device variable to the GPU if available.
import torch
import torch.nn as nn
from torchinfo import summary
import torchvision
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import pandas as pddevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)cuda:0VGGNet-16
Models are available in the torchvision.models subpackage. More information about this subpackage can be found here: https://pytorch.org/vision/stable/models.html. As a first example, I am instantiating an instance of the VGGNet-16 architecture. I also move the model to the GPU using the to() method. The pretrained parameter is used to load in pre-trained weights. This allows you to either (1) use the pre-trained model to predict to new data or (2) instantiate an instance of the model using the pre-trained weights as opposed to random weights that can then be fine-tuned on new data. If you run this model with the pretrained parameter set to True, the weights will be downloaded to your local device or your Google Drive if you are working in CoLab.
modelVGG = torchvision.models.vgg16(pretrained=True).to(device)C:\Users\vidcg\ANACON~1\envs\torchENV\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
C:\Users\vidcg\ANACON~1\envs\torchENV\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)I next use the summary function from torchinfo to print a summary of the model if a mini-batch with a shape of (12,3,256,256) is passed through the network. This is a fairly large model with 138,357,544 trainable parameters and an estimated total size of 814 MB. Again, we will not discuss the components of this architecture here since it was explored in the lecture module.
summary(modelVGG, (12, 3, 256, 256))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGG [12, 1000] --
├─Sequential: 1-1 [12, 512, 8, 8] --
│ └─Conv2d: 2-1 [12, 64, 256, 256] 1,792
│ └─ReLU: 2-2 [12, 64, 256, 256] --
│ └─Conv2d: 2-3 [12, 64, 256, 256] 36,928
│ └─ReLU: 2-4 [12, 64, 256, 256] --
│ └─MaxPool2d: 2-5 [12, 64, 128, 128] --
│ └─Conv2d: 2-6 [12, 128, 128, 128] 73,856
│ └─ReLU: 2-7 [12, 128, 128, 128] --
│ └─Conv2d: 2-8 [12, 128, 128, 128] 147,584
│ └─ReLU: 2-9 [12, 128, 128, 128] --
│ └─MaxPool2d: 2-10 [12, 128, 64, 64] --
│ └─Conv2d: 2-11 [12, 256, 64, 64] 295,168
│ └─ReLU: 2-12 [12, 256, 64, 64] --
│ └─Conv2d: 2-13 [12, 256, 64, 64] 590,080
│ └─ReLU: 2-14 [12, 256, 64, 64] --
│ └─Conv2d: 2-15 [12, 256, 64, 64] 590,080
│ └─ReLU: 2-16 [12, 256, 64, 64] --
│ └─MaxPool2d: 2-17 [12, 256, 32, 32] --
│ └─Conv2d: 2-18 [12, 512, 32, 32] 1,180,160
│ └─ReLU: 2-19 [12, 512, 32, 32] --
│ └─Conv2d: 2-20 [12, 512, 32, 32] 2,359,808
│ └─ReLU: 2-21 [12, 512, 32, 32] --
│ └─Conv2d: 2-22 [12, 512, 32, 32] 2,359,808
│ └─ReLU: 2-23 [12, 512, 32, 32] --
│ └─MaxPool2d: 2-24 [12, 512, 16, 16] --
│ └─Conv2d: 2-25 [12, 512, 16, 16] 2,359,808
│ └─ReLU: 2-26 [12, 512, 16, 16] --
│ └─Conv2d: 2-27 [12, 512, 16, 16] 2,359,808
│ └─ReLU: 2-28 [12, 512, 16, 16] --
│ └─Conv2d: 2-29 [12, 512, 16, 16] 2,359,808
│ └─ReLU: 2-30 [12, 512, 16, 16] --
│ └─MaxPool2d: 2-31 [12, 512, 8, 8] --
├─AdaptiveAvgPool2d: 1-2 [12, 512, 7, 7] --
├─Sequential: 1-3 [12, 1000] --
│ └─Linear: 2-32 [12, 4096] 102,764,544
│ └─ReLU: 2-33 [12, 4096] --
│ └─Dropout: 2-34 [12, 4096] --
│ └─Linear: 2-35 [12, 4096] 16,781,312
│ └─ReLU: 2-36 [12, 4096] --
│ └─Dropout: 2-37 [12, 4096] --
│ └─Linear: 2-38 [12, 1000] 4,097,000
==========================================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
Total mult-adds (G): 242.23
==========================================================================================
Input size (MB): 9.44
Forward/backward pass size (MB): 1699.58
Params size (MB): 553.43
Estimated Total Size (MB): 2262.44
==========================================================================================
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGG [12, 1000] --
├─Sequential: 1-1 [12, 512, 8, 8] --
│ └─Conv2d: 2-1 [12, 64, 256, 256] 1,792
│ └─ReLU: 2-2 [12, 64, 256, 256] --
│ └─Conv2d: 2-3 [12, 64, 256, 256] 36,928
│ └─ReLU: 2-4 [12, 64, 256, 256] --
│ └─MaxPool2d: 2-5 [12, 64, 128, 128] --
│ └─Conv2d: 2-6 [12, 128, 128, 128] 73,856
│ └─ReLU: 2-7 [12, 128, 128, 128] --
│ └─Conv2d: 2-8 [12, 128, 128, 128] 147,584
│ └─ReLU: 2-9 [12, 128, 128, 128] --
│ └─MaxPool2d: 2-10 [12, 128, 64, 64] --
│ └─Conv2d: 2-11 [12, 256, 64, 64] 295,168
│ └─ReLU: 2-12 [12, 256, 64, 64] --
│ └─Conv2d: 2-13 [12, 256, 64, 64] 590,080
│ └─ReLU: 2-14 [12, 256, 64, 64] --
│ └─Conv2d: 2-15 [12, 256, 64, 64] 590,080
│ └─ReLU: 2-16 [12, 256, 64, 64] --
│ └─MaxPool2d: 2-17 [12, 256, 32, 32] --
│ └─Conv2d: 2-18 [12, 512, 32, 32] 1,180,160
│ └─ReLU: 2-19 [12, 512, 32, 32] --
│ └─Conv2d: 2-20 [12, 512, 32, 32] 2,359,808
│ └─ReLU: 2-21 [12, 512, 32, 32] --
│ └─Conv2d: 2-22 [12, 512, 32, 32] 2,359,808
│ └─ReLU: 2-23 [12, 512, 32, 32] --
│ └─MaxPool2d: 2-24 [12, 512, 16, 16] --
│ └─Conv2d: 2-25 [12, 512, 16, 16] 2,359,808
│ └─ReLU: 2-26 [12, 512, 16, 16] --
│ └─Conv2d: 2-27 [12, 512, 16, 16] 2,359,808
│ └─ReLU: 2-28 [12, 512, 16, 16] --
│ └─Conv2d: 2-29 [12, 512, 16, 16] 2,359,808
│ └─ReLU: 2-30 [12, 512, 16, 16] --
│ └─MaxPool2d: 2-31 [12, 512, 8, 8] --
├─AdaptiveAvgPool2d: 1-2 [12, 512, 7, 7] --
├─Sequential: 1-3 [12, 1000] --
│ └─Linear: 2-32 [12, 4096] 102,764,544
│ └─ReLU: 2-33 [12, 4096] --
│ └─Dropout: 2-34 [12, 4096] --
│ └─Linear: 2-35 [12, 4096] 16,781,312
│ └─ReLU: 2-36 [12, 4096] --
│ └─Dropout: 2-37 [12, 4096] --
│ └─Linear: 2-38 [12, 1000] 4,097,000
==========================================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
Total mult-adds (G): 242.23
==========================================================================================
Input size (MB): 9.44
Forward/backward pass size (MB): 1699.58
Params size (MB): 553.43
Estimated Total Size (MB): 2262.44
==========================================================================================There are sometimes different flavors or implementations of the same model available. In the example below, I have created an instance of the VGGNet-16 architecture that incorporates batch normalization using the vgg16_bn() function. Printing the summary, you can see that the model now includes batch normalization layers. This also increases the required memory size of the model and the number of trainable parameters.
modelVGG = torchvision.models.vgg16_bn(pretrained=True).to(device)C:\Users\vidcg\ANACON~1\envs\torchENV\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG16_BN_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_BN_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)summary(modelVGG, (12, 3, 256, 256))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGG [12, 1000] --
├─Sequential: 1-1 [12, 512, 8, 8] --
│ └─Conv2d: 2-1 [12, 64, 256, 256] 1,792
│ └─BatchNorm2d: 2-2 [12, 64, 256, 256] 128
│ └─ReLU: 2-3 [12, 64, 256, 256] --
│ └─Conv2d: 2-4 [12, 64, 256, 256] 36,928
│ └─BatchNorm2d: 2-5 [12, 64, 256, 256] 128
│ └─ReLU: 2-6 [12, 64, 256, 256] --
│ └─MaxPool2d: 2-7 [12, 64, 128, 128] --
│ └─Conv2d: 2-8 [12, 128, 128, 128] 73,856
│ └─BatchNorm2d: 2-9 [12, 128, 128, 128] 256
│ └─ReLU: 2-10 [12, 128, 128, 128] --
│ └─Conv2d: 2-11 [12, 128, 128, 128] 147,584
│ └─BatchNorm2d: 2-12 [12, 128, 128, 128] 256
│ └─ReLU: 2-13 [12, 128, 128, 128] --
│ └─MaxPool2d: 2-14 [12, 128, 64, 64] --
│ └─Conv2d: 2-15 [12, 256, 64, 64] 295,168
│ └─BatchNorm2d: 2-16 [12, 256, 64, 64] 512
│ └─ReLU: 2-17 [12, 256, 64, 64] --
│ └─Conv2d: 2-18 [12, 256, 64, 64] 590,080
│ └─BatchNorm2d: 2-19 [12, 256, 64, 64] 512
│ └─ReLU: 2-20 [12, 256, 64, 64] --
│ └─Conv2d: 2-21 [12, 256, 64, 64] 590,080
│ └─BatchNorm2d: 2-22 [12, 256, 64, 64] 512
│ └─ReLU: 2-23 [12, 256, 64, 64] --
│ └─MaxPool2d: 2-24 [12, 256, 32, 32] --
│ └─Conv2d: 2-25 [12, 512, 32, 32] 1,180,160
│ └─BatchNorm2d: 2-26 [12, 512, 32, 32] 1,024
│ └─ReLU: 2-27 [12, 512, 32, 32] --
│ └─Conv2d: 2-28 [12, 512, 32, 32] 2,359,808
│ └─BatchNorm2d: 2-29 [12, 512, 32, 32] 1,024
│ └─ReLU: 2-30 [12, 512, 32, 32] --
│ └─Conv2d: 2-31 [12, 512, 32, 32] 2,359,808
│ └─BatchNorm2d: 2-32 [12, 512, 32, 32] 1,024
│ └─ReLU: 2-33 [12, 512, 32, 32] --
│ └─MaxPool2d: 2-34 [12, 512, 16, 16] --
│ └─Conv2d: 2-35 [12, 512, 16, 16] 2,359,808
│ └─BatchNorm2d: 2-36 [12, 512, 16, 16] 1,024
│ └─ReLU: 2-37 [12, 512, 16, 16] --
│ └─Conv2d: 2-38 [12, 512, 16, 16] 2,359,808
│ └─BatchNorm2d: 2-39 [12, 512, 16, 16] 1,024
│ └─ReLU: 2-40 [12, 512, 16, 16] --
│ └─Conv2d: 2-41 [12, 512, 16, 16] 2,359,808
│ └─BatchNorm2d: 2-42 [12, 512, 16, 16] 1,024
│ └─ReLU: 2-43 [12, 512, 16, 16] --
│ └─MaxPool2d: 2-44 [12, 512, 8, 8] --
├─AdaptiveAvgPool2d: 1-2 [12, 512, 7, 7] --
├─Sequential: 1-3 [12, 1000] --
│ └─Linear: 2-45 [12, 4096] 102,764,544
│ └─ReLU: 2-46 [12, 4096] --
│ └─Dropout: 2-47 [12, 4096] --
│ └─Linear: 2-48 [12, 4096] 16,781,312
│ └─ReLU: 2-49 [12, 4096] --
│ └─Dropout: 2-50 [12, 4096] --
│ └─Linear: 2-51 [12, 1000] 4,097,000
==========================================================================================
Total params: 138,365,992
Trainable params: 138,365,992
Non-trainable params: 0
Total mult-adds (G): 242.23
==========================================================================================
Input size (MB): 9.44
Forward/backward pass size (MB): 3398.27
Params size (MB): 553.46
Estimated Total Size (MB): 3961.17
==========================================================================================
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGG [12, 1000] --
├─Sequential: 1-1 [12, 512, 8, 8] --
│ └─Conv2d: 2-1 [12, 64, 256, 256] 1,792
│ └─BatchNorm2d: 2-2 [12, 64, 256, 256] 128
│ └─ReLU: 2-3 [12, 64, 256, 256] --
│ └─Conv2d: 2-4 [12, 64, 256, 256] 36,928
│ └─BatchNorm2d: 2-5 [12, 64, 256, 256] 128
│ └─ReLU: 2-6 [12, 64, 256, 256] --
│ └─MaxPool2d: 2-7 [12, 64, 128, 128] --
│ └─Conv2d: 2-8 [12, 128, 128, 128] 73,856
│ └─BatchNorm2d: 2-9 [12, 128, 128, 128] 256
│ └─ReLU: 2-10 [12, 128, 128, 128] --
│ └─Conv2d: 2-11 [12, 128, 128, 128] 147,584
│ └─BatchNorm2d: 2-12 [12, 128, 128, 128] 256
│ └─ReLU: 2-13 [12, 128, 128, 128] --
│ └─MaxPool2d: 2-14 [12, 128, 64, 64] --
│ └─Conv2d: 2-15 [12, 256, 64, 64] 295,168
│ └─BatchNorm2d: 2-16 [12, 256, 64, 64] 512
│ └─ReLU: 2-17 [12, 256, 64, 64] --
│ └─Conv2d: 2-18 [12, 256, 64, 64] 590,080
│ └─BatchNorm2d: 2-19 [12, 256, 64, 64] 512
│ └─ReLU: 2-20 [12, 256, 64, 64] --
│ └─Conv2d: 2-21 [12, 256, 64, 64] 590,080
│ └─BatchNorm2d: 2-22 [12, 256, 64, 64] 512
│ └─ReLU: 2-23 [12, 256, 64, 64] --
│ └─MaxPool2d: 2-24 [12, 256, 32, 32] --
│ └─Conv2d: 2-25 [12, 512, 32, 32] 1,180,160
│ └─BatchNorm2d: 2-26 [12, 512, 32, 32] 1,024
│ └─ReLU: 2-27 [12, 512, 32, 32] --
│ └─Conv2d: 2-28 [12, 512, 32, 32] 2,359,808
│ └─BatchNorm2d: 2-29 [12, 512, 32, 32] 1,024
│ └─ReLU: 2-30 [12, 512, 32, 32] --
│ └─Conv2d: 2-31 [12, 512, 32, 32] 2,359,808
│ └─BatchNorm2d: 2-32 [12, 512, 32, 32] 1,024
│ └─ReLU: 2-33 [12, 512, 32, 32] --
│ └─MaxPool2d: 2-34 [12, 512, 16, 16] --
│ └─Conv2d: 2-35 [12, 512, 16, 16] 2,359,808
│ └─BatchNorm2d: 2-36 [12, 512, 16, 16] 1,024
│ └─ReLU: 2-37 [12, 512, 16, 16] --
│ └─Conv2d: 2-38 [12, 512, 16, 16] 2,359,808
│ └─BatchNorm2d: 2-39 [12, 512, 16, 16] 1,024
│ └─ReLU: 2-40 [12, 512, 16, 16] --
│ └─Conv2d: 2-41 [12, 512, 16, 16] 2,359,808
│ └─BatchNorm2d: 2-42 [12, 512, 16, 16] 1,024
│ └─ReLU: 2-43 [12, 512, 16, 16] --
│ └─MaxPool2d: 2-44 [12, 512, 8, 8] --
├─AdaptiveAvgPool2d: 1-2 [12, 512, 7, 7] --
├─Sequential: 1-3 [12, 1000] --
│ └─Linear: 2-45 [12, 4096] 102,764,544
│ └─ReLU: 2-46 [12, 4096] --
│ └─Dropout: 2-47 [12, 4096] --
│ └─Linear: 2-48 [12, 4096] 16,781,312
│ └─ReLU: 2-49 [12, 4096] --
│ └─Dropout: 2-50 [12, 4096] --
│ └─Linear: 2-51 [12, 1000] 4,097,000
==========================================================================================
Total params: 138,365,992
Trainable params: 138,365,992
Non-trainable params: 0
Total mult-adds (G): 242.23
==========================================================================================
Input size (MB): 9.44
Forward/backward pass size (MB): 3398.27
Params size (MB): 553.46
Estimated Total Size (MB): 3961.17
==========================================================================================ResNet
Similar to the VGGNet-16 examples, ResNet models are also made available through torchvision with pre-trained weights from ImageNet. Below, I am instantiating an instance of the ResNet-34 architecture with pre-trained weights. Many models have an expected number of channels and height and width of provided images. So, it is common to need to perform pre-processing, as you will see below. This ResNet architecture expects 3-band, RGB images with spatial dimensions of 224x224. In contrast, the VGGNet-16 architecture above expects spatial dimensions of 256x256.
Printing a summary for the model, you can see that the ResNet-34 architecture has fewer overall parameters and trainable parameters in comparison to VGGNet-16.
modelRN34 = torchvision.models.resnet34(pretrained=True).to(device)C:\Users\vidcg\ANACON~1\envs\torchENV\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet34_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet34_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)summary(modelRN34, (12, 3, 224, 224))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [12, 1000] --
├─Conv2d: 1-1 [12, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [12, 64, 112, 112] 128
├─ReLU: 1-3 [12, 64, 112, 112] --
├─MaxPool2d: 1-4 [12, 64, 56, 56] --
├─Sequential: 1-5 [12, 64, 56, 56] --
│ └─BasicBlock: 2-1 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [12, 64, 56, 56] --
│ └─BasicBlock: 2-2 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [12, 64, 56, 56] --
│ └─BasicBlock: 2-3 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-13 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-14 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-15 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-16 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-17 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-18 [12, 64, 56, 56] --
├─Sequential: 1-6 [12, 128, 28, 28] --
│ └─BasicBlock: 2-4 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-19 [12, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-20 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-21 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-22 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-23 [12, 128, 28, 28] 256
│ │ └─Sequential: 3-24 [12, 128, 28, 28] 8,448
│ │ └─ReLU: 3-25 [12, 128, 28, 28] --
│ └─BasicBlock: 2-5 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-26 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-27 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-28 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-29 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-30 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-31 [12, 128, 28, 28] --
│ └─BasicBlock: 2-6 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-32 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-33 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-34 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-35 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-36 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-37 [12, 128, 28, 28] --
│ └─BasicBlock: 2-7 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-38 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-39 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-40 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-41 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-42 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-43 [12, 128, 28, 28] --
├─Sequential: 1-7 [12, 256, 14, 14] --
│ └─BasicBlock: 2-8 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-44 [12, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-45 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-46 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-47 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-48 [12, 256, 14, 14] 512
│ │ └─Sequential: 3-49 [12, 256, 14, 14] 33,280
│ │ └─ReLU: 3-50 [12, 256, 14, 14] --
│ └─BasicBlock: 2-9 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-51 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-52 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-53 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-54 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-55 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-56 [12, 256, 14, 14] --
│ └─BasicBlock: 2-10 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-57 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-58 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-59 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-60 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-61 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-62 [12, 256, 14, 14] --
│ └─BasicBlock: 2-11 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-63 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-64 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-65 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-66 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-67 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-68 [12, 256, 14, 14] --
│ └─BasicBlock: 2-12 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-69 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-70 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-71 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-72 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-73 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-74 [12, 256, 14, 14] --
│ └─BasicBlock: 2-13 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-75 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-76 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-77 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-78 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-79 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-80 [12, 256, 14, 14] --
├─Sequential: 1-8 [12, 512, 7, 7] --
│ └─BasicBlock: 2-14 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-81 [12, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-82 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-83 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-84 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-85 [12, 512, 7, 7] 1,024
│ │ └─Sequential: 3-86 [12, 512, 7, 7] 132,096
│ │ └─ReLU: 3-87 [12, 512, 7, 7] --
│ └─BasicBlock: 2-15 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-88 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-89 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-90 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-91 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-92 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-93 [12, 512, 7, 7] --
│ └─BasicBlock: 2-16 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-94 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-95 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-96 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-97 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-98 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-99 [12, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [12, 512, 1, 1] --
├─Linear: 1-10 [12, 1000] 513,000
==========================================================================================
Total params: 21,797,672
Trainable params: 21,797,672
Non-trainable params: 0
Total mult-adds (G): 43.97
==========================================================================================
Input size (MB): 7.23
Forward/backward pass size (MB): 717.81
Params size (MB): 87.19
Estimated Total Size (MB): 812.23
==========================================================================================
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [12, 1000] --
├─Conv2d: 1-1 [12, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [12, 64, 112, 112] 128
├─ReLU: 1-3 [12, 64, 112, 112] --
├─MaxPool2d: 1-4 [12, 64, 56, 56] --
├─Sequential: 1-5 [12, 64, 56, 56] --
│ └─BasicBlock: 2-1 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [12, 64, 56, 56] --
│ └─BasicBlock: 2-2 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [12, 64, 56, 56] --
│ └─BasicBlock: 2-3 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-13 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-14 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-15 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-16 [12, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-17 [12, 64, 56, 56] 128
│ │ └─ReLU: 3-18 [12, 64, 56, 56] --
├─Sequential: 1-6 [12, 128, 28, 28] --
│ └─BasicBlock: 2-4 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-19 [12, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-20 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-21 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-22 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-23 [12, 128, 28, 28] 256
│ │ └─Sequential: 3-24 [12, 128, 28, 28] 8,448
│ │ └─ReLU: 3-25 [12, 128, 28, 28] --
│ └─BasicBlock: 2-5 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-26 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-27 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-28 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-29 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-30 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-31 [12, 128, 28, 28] --
│ └─BasicBlock: 2-6 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-32 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-33 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-34 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-35 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-36 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-37 [12, 128, 28, 28] --
│ └─BasicBlock: 2-7 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-38 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-39 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-40 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-41 [12, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-42 [12, 128, 28, 28] 256
│ │ └─ReLU: 3-43 [12, 128, 28, 28] --
├─Sequential: 1-7 [12, 256, 14, 14] --
│ └─BasicBlock: 2-8 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-44 [12, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-45 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-46 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-47 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-48 [12, 256, 14, 14] 512
│ │ └─Sequential: 3-49 [12, 256, 14, 14] 33,280
│ │ └─ReLU: 3-50 [12, 256, 14, 14] --
│ └─BasicBlock: 2-9 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-51 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-52 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-53 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-54 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-55 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-56 [12, 256, 14, 14] --
│ └─BasicBlock: 2-10 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-57 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-58 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-59 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-60 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-61 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-62 [12, 256, 14, 14] --
│ └─BasicBlock: 2-11 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-63 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-64 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-65 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-66 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-67 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-68 [12, 256, 14, 14] --
│ └─BasicBlock: 2-12 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-69 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-70 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-71 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-72 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-73 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-74 [12, 256, 14, 14] --
│ └─BasicBlock: 2-13 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-75 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-76 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-77 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-78 [12, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-79 [12, 256, 14, 14] 512
│ │ └─ReLU: 3-80 [12, 256, 14, 14] --
├─Sequential: 1-8 [12, 512, 7, 7] --
│ └─BasicBlock: 2-14 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-81 [12, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-82 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-83 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-84 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-85 [12, 512, 7, 7] 1,024
│ │ └─Sequential: 3-86 [12, 512, 7, 7] 132,096
│ │ └─ReLU: 3-87 [12, 512, 7, 7] --
│ └─BasicBlock: 2-15 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-88 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-89 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-90 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-91 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-92 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-93 [12, 512, 7, 7] --
│ └─BasicBlock: 2-16 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-94 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-95 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-96 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-97 [12, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-98 [12, 512, 7, 7] 1,024
│ │ └─ReLU: 3-99 [12, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [12, 512, 1, 1] --
├─Linear: 1-10 [12, 1000] 513,000
==========================================================================================
Total params: 21,797,672
Trainable params: 21,797,672
Non-trainable params: 0
Total mult-adds (G): 43.97
==========================================================================================
Input size (MB): 7.23
Forward/backward pass size (MB): 717.81
Params size (MB): 87.19
Estimated Total Size (MB): 812.23
==========================================================================================By default, all trainable parameters can be updated if the model is trained further using new data. In other words, the computational graph and gradients will be maintained. However, it is possible to freeze parameters so that they cannot be updated. Below, I am defining a function, which I modified from the website included in the comment, which will freeze all model parameters if the freeze parameter is set to True. If I run this function on the ResNet-34 model instance then print a summary, you can see that now none of the parameters are trainable.
It is generally more common to freeze only some of the initially trainable parameters in a model as opposed to all of them. I will demonstrate this next and also in some of the later semantic segmentation modules.
#https://pytorch.org/tutorials/beginner/finetuning_torchvision_models_tutorial.html
def set_parameter_requires_grad(model, freeze=True):
if freeze == True:
for param in model.parameters():
param.requires_grad = Falseset_parameter_requires_grad(modelRN34, freeze=True)summary(modelRN34, (12, 3, 224, 224))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [12, 1000] --
├─Conv2d: 1-1 [12, 64, 112, 112] (9,408)
├─BatchNorm2d: 1-2 [12, 64, 112, 112] (128)
├─ReLU: 1-3 [12, 64, 112, 112] --
├─MaxPool2d: 1-4 [12, 64, 56, 56] --
├─Sequential: 1-5 [12, 64, 56, 56] --
│ └─BasicBlock: 2-1 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-2 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-3 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-5 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-6 [12, 64, 56, 56] --
│ └─BasicBlock: 2-2 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-8 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-9 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-11 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-12 [12, 64, 56, 56] --
│ └─BasicBlock: 2-3 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-13 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-14 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-15 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-16 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-17 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-18 [12, 64, 56, 56] --
├─Sequential: 1-6 [12, 128, 28, 28] --
│ └─BasicBlock: 2-4 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-19 [12, 128, 28, 28] (73,728)
│ │ └─BatchNorm2d: 3-20 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-21 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-22 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-23 [12, 128, 28, 28] (256)
│ │ └─Sequential: 3-24 [12, 128, 28, 28] (8,448)
│ │ └─ReLU: 3-25 [12, 128, 28, 28] --
│ └─BasicBlock: 2-5 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-26 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-27 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-28 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-29 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-30 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-31 [12, 128, 28, 28] --
│ └─BasicBlock: 2-6 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-32 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-33 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-34 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-35 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-36 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-37 [12, 128, 28, 28] --
│ └─BasicBlock: 2-7 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-38 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-39 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-40 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-41 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-42 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-43 [12, 128, 28, 28] --
├─Sequential: 1-7 [12, 256, 14, 14] --
│ └─BasicBlock: 2-8 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-44 [12, 256, 14, 14] (294,912)
│ │ └─BatchNorm2d: 3-45 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-46 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-47 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-48 [12, 256, 14, 14] (512)
│ │ └─Sequential: 3-49 [12, 256, 14, 14] (33,280)
│ │ └─ReLU: 3-50 [12, 256, 14, 14] --
│ └─BasicBlock: 2-9 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-51 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-52 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-53 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-54 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-55 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-56 [12, 256, 14, 14] --
│ └─BasicBlock: 2-10 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-57 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-58 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-59 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-60 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-61 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-62 [12, 256, 14, 14] --
│ └─BasicBlock: 2-11 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-63 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-64 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-65 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-66 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-67 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-68 [12, 256, 14, 14] --
│ └─BasicBlock: 2-12 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-69 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-70 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-71 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-72 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-73 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-74 [12, 256, 14, 14] --
│ └─BasicBlock: 2-13 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-75 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-76 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-77 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-78 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-79 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-80 [12, 256, 14, 14] --
├─Sequential: 1-8 [12, 512, 7, 7] --
│ └─BasicBlock: 2-14 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-81 [12, 512, 7, 7] (1,179,648)
│ │ └─BatchNorm2d: 3-82 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-83 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-84 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-85 [12, 512, 7, 7] (1,024)
│ │ └─Sequential: 3-86 [12, 512, 7, 7] (132,096)
│ │ └─ReLU: 3-87 [12, 512, 7, 7] --
│ └─BasicBlock: 2-15 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-88 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-89 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-90 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-91 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-92 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-93 [12, 512, 7, 7] --
│ └─BasicBlock: 2-16 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-94 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-95 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-96 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-97 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-98 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-99 [12, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [12, 512, 1, 1] --
├─Linear: 1-10 [12, 1000] (513,000)
==========================================================================================
Total params: 21,797,672
Trainable params: 0
Non-trainable params: 21,797,672
Total mult-adds (G): 43.97
==========================================================================================
Input size (MB): 7.23
Forward/backward pass size (MB): 717.81
Params size (MB): 87.19
Estimated Total Size (MB): 812.23
==========================================================================================
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [12, 1000] --
├─Conv2d: 1-1 [12, 64, 112, 112] (9,408)
├─BatchNorm2d: 1-2 [12, 64, 112, 112] (128)
├─ReLU: 1-3 [12, 64, 112, 112] --
├─MaxPool2d: 1-4 [12, 64, 56, 56] --
├─Sequential: 1-5 [12, 64, 56, 56] --
│ └─BasicBlock: 2-1 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-2 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-3 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-5 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-6 [12, 64, 56, 56] --
│ └─BasicBlock: 2-2 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-8 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-9 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-11 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-12 [12, 64, 56, 56] --
│ └─BasicBlock: 2-3 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-13 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-14 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-15 [12, 64, 56, 56] --
│ │ └─Conv2d: 3-16 [12, 64, 56, 56] (36,864)
│ │ └─BatchNorm2d: 3-17 [12, 64, 56, 56] (128)
│ │ └─ReLU: 3-18 [12, 64, 56, 56] --
├─Sequential: 1-6 [12, 128, 28, 28] --
│ └─BasicBlock: 2-4 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-19 [12, 128, 28, 28] (73,728)
│ │ └─BatchNorm2d: 3-20 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-21 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-22 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-23 [12, 128, 28, 28] (256)
│ │ └─Sequential: 3-24 [12, 128, 28, 28] (8,448)
│ │ └─ReLU: 3-25 [12, 128, 28, 28] --
│ └─BasicBlock: 2-5 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-26 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-27 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-28 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-29 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-30 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-31 [12, 128, 28, 28] --
│ └─BasicBlock: 2-6 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-32 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-33 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-34 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-35 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-36 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-37 [12, 128, 28, 28] --
│ └─BasicBlock: 2-7 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-38 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-39 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-40 [12, 128, 28, 28] --
│ │ └─Conv2d: 3-41 [12, 128, 28, 28] (147,456)
│ │ └─BatchNorm2d: 3-42 [12, 128, 28, 28] (256)
│ │ └─ReLU: 3-43 [12, 128, 28, 28] --
├─Sequential: 1-7 [12, 256, 14, 14] --
│ └─BasicBlock: 2-8 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-44 [12, 256, 14, 14] (294,912)
│ │ └─BatchNorm2d: 3-45 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-46 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-47 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-48 [12, 256, 14, 14] (512)
│ │ └─Sequential: 3-49 [12, 256, 14, 14] (33,280)
│ │ └─ReLU: 3-50 [12, 256, 14, 14] --
│ └─BasicBlock: 2-9 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-51 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-52 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-53 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-54 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-55 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-56 [12, 256, 14, 14] --
│ └─BasicBlock: 2-10 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-57 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-58 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-59 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-60 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-61 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-62 [12, 256, 14, 14] --
│ └─BasicBlock: 2-11 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-63 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-64 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-65 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-66 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-67 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-68 [12, 256, 14, 14] --
│ └─BasicBlock: 2-12 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-69 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-70 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-71 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-72 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-73 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-74 [12, 256, 14, 14] --
│ └─BasicBlock: 2-13 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-75 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-76 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-77 [12, 256, 14, 14] --
│ │ └─Conv2d: 3-78 [12, 256, 14, 14] (589,824)
│ │ └─BatchNorm2d: 3-79 [12, 256, 14, 14] (512)
│ │ └─ReLU: 3-80 [12, 256, 14, 14] --
├─Sequential: 1-8 [12, 512, 7, 7] --
│ └─BasicBlock: 2-14 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-81 [12, 512, 7, 7] (1,179,648)
│ │ └─BatchNorm2d: 3-82 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-83 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-84 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-85 [12, 512, 7, 7] (1,024)
│ │ └─Sequential: 3-86 [12, 512, 7, 7] (132,096)
│ │ └─ReLU: 3-87 [12, 512, 7, 7] --
│ └─BasicBlock: 2-15 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-88 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-89 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-90 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-91 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-92 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-93 [12, 512, 7, 7] --
│ └─BasicBlock: 2-16 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-94 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-95 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-96 [12, 512, 7, 7] --
│ │ └─Conv2d: 3-97 [12, 512, 7, 7] (2,359,296)
│ │ └─BatchNorm2d: 3-98 [12, 512, 7, 7] (1,024)
│ │ └─ReLU: 3-99 [12, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [12, 512, 1, 1] --
├─Linear: 1-10 [12, 1000] (513,000)
==========================================================================================
Total params: 21,797,672
Trainable params: 0
Non-trainable params: 21,797,672
Total mult-adds (G): 43.97
==========================================================================================
Input size (MB): 7.23
Forward/backward pass size (MB): 717.81
Params size (MB): 87.19
Estimated Total Size (MB): 812.23
==========================================================================================I will now build a function that allows the user to specify which ResNet architecture is desired (“18”, “34”, “50”, “101”, or “152”), the number of input channels, the number of classes being differentiated, whether or not to freeze the parameters associated with the convolutional component of the model, and whether or not to use pre-trained weights. One common issue with pre-trained models and pre-defined architectures is that they expect a certain input image size. This is a result of the flattening and fully connected components of the model. If the size of the spatial dimensions are not consistent with the original data used to train the model then the length of the flattened tensor following the convolutional operations will also not be consistent. This is because the length of the flattened array is Number of Final Feature Maps X Height X Width. So, one common means to generalize these pre-trained models to allow for images of a different input size to be provided and/or for the model to be trained for a new task, is to redefine the fully connected component of the model but maintain the convolutional component. The weights from the convolutional component can then be used while new weights will be learned for the newly defined fully connected components. It is possible to either (1) not initialize the parameters associated with the convolutional component using pre-trained weights, (2) initialize the models using pre-trained weights but allow them to be further trained or updated, or (3) lock or freeze the parameters associated with the convolutional component while updating those associated with the fully connected component.
Note that one component that makes the ResNet architecture used here easier to modify is the use of nn.AdaptiveAvgPool2d() at the end of the convolutional component of the architecture. This allows for a fixed output size to be fed to the fully connected component of the model. Or, the model can more easily be generalized to variable input sizes. However, the number of outputs from the fully connected layer still needs to be modified to match the number of classes being differentiated.
Let’s step through this function. Which ResNet architecture is returned depends on the user’s input to the ResNet argument. Within the first series of control flow statements, the desired architecture is initialized. The pretrained parameter determines whether or not pre-trained weights will be used. The default is True. If pre-trained weights are desired, then the freeze parameter can be used to specify if the parameters associated with the convolutional component of the architecture will be trainable or not. This is accomplished using the set_parameter_requires_grad() function defined above. If the freeze parameter is set to True, all weights will be frozen. If it is set to False, they will remain trainable. If freeze is set to True, then all the model parameters will be frozen, not just those associated with the convolutional component. To unfreeze the parameters associated with the fully connected component at the end of the architecture, I then replace this component with a new nn.Linear() layer with the correct number of output classes, which can be defined by the user.
In order to generalize this model further, I also allow the user to specify the number of input channels. This requires replacing the first 2D convolution layer, which expects three channels. This will also require that the weights be updated for this convolutional layer during the training process. I also replace the batch normalization layer following this first convolutional layer so that the associated parameters can also be updated.
The order here matters. The first 2D convolution and batch normalization layers and the fully connected layer at the end of the architecture must be replaced after freezing the model parameters/weights since these layers should be trainable. Replacing them will unfreeze the weights since this is the default state.
# https://stackoverflow.com/questions/62629114/how-to-modify-resnet-50-with-4-channels-as-input-using-pre-trained-weights-in-py
# https://discuss.pytorch.org/t/transfer-learning-usage-with-different-input-size/20744
def initialize_model(resNet, nChn, nCls, freeze=True, pretrained=True):
if resNet == "18":
model = torchvision.models.resnet18(pretrained=pretrained)
elif resNet == "34":
model = torchvision.models.resnet34(pretrained=pretrained)
elif resNet == "50":
model = torchvision.models.resnet50(pretrained=pretrained)
elif resNet == "101":
model = torchvision.models.resnet101(pretrained=pretrained)
elif resNet == "152":
model = torchvision.models.resnet152(pretrained=pretrained)
else:
model = torchvision.models.resnet34(pretrained=pretrained)
if pretrained == True:
set_parameter_requires_grad(model, freeze)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, nCls)
if nChn != 3:
model.conv1 = nn.Conv2d(nChn, 64, kernel_size=7, stride=2, padding=3, bias=False)
model.bn1 = nn.BatchNorm2d(64)
return modelI next instantiate an instance of the model with a ResNet-34 architecture, 1 input channel (i.e., the network will accept a grayscale image), 5 classes being differentiated, freezing the convolutional component of the model, and using pre-trained weights. I then print a summary for this model using an input size of (3, 512, 512). Note that some of the parameters are trainable, specifically those associated with the first convolutional layer, first batch normalization layer, and fully connected layer at the end of the model, while some are not trainable, specifically those associated with the convolutional component of the architecture other than the first 2D convolution layer and first batch normalization layer. If you run this model with the freeze parameter set to False, all weights will be trainable. If you run it with the pretrained parameter set to False then the model will initialize with random weights as opposed to pre-trained weights and all weights will be trainable.
Freezing weights can greatly decrease the computational load and time needed to train models. Whether or not suitable output can be generated without training all weights will depend on the use case. It is also possible to freeze and/or unfreeze parameters at specific points in the training process, such as at a defined epoch.
I find manually altering these provided architectures to be tricky. However, you can generally find help online.
model = initialize_model(resNet="34", nChn=1, nCls=5, freeze=True, pretrained=True).to(device)summary(model, (12, 1, 512, 512))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [12, 5] --
├─Conv2d: 1-1 [12, 64, 256, 256] 3,136
├─BatchNorm2d: 1-2 [12, 64, 256, 256] 128
├─ReLU: 1-3 [12, 64, 256, 256] --
├─MaxPool2d: 1-4 [12, 64, 128, 128] --
├─Sequential: 1-5 [12, 64, 128, 128] --
│ └─BasicBlock: 2-1 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-1 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-2 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-3 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-4 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-5 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-6 [12, 64, 128, 128] --
│ └─BasicBlock: 2-2 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-7 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-8 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-9 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-10 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-11 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-12 [12, 64, 128, 128] --
│ └─BasicBlock: 2-3 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-13 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-14 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-15 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-16 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-17 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-18 [12, 64, 128, 128] --
├─Sequential: 1-6 [12, 128, 64, 64] --
│ └─BasicBlock: 2-4 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-19 [12, 128, 64, 64] (73,728)
│ │ └─BatchNorm2d: 3-20 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-21 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-22 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-23 [12, 128, 64, 64] (256)
│ │ └─Sequential: 3-24 [12, 128, 64, 64] (8,448)
│ │ └─ReLU: 3-25 [12, 128, 64, 64] --
│ └─BasicBlock: 2-5 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-26 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-27 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-28 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-29 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-30 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-31 [12, 128, 64, 64] --
│ └─BasicBlock: 2-6 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-32 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-33 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-34 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-35 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-36 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-37 [12, 128, 64, 64] --
│ └─BasicBlock: 2-7 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-38 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-39 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-40 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-41 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-42 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-43 [12, 128, 64, 64] --
├─Sequential: 1-7 [12, 256, 32, 32] --
│ └─BasicBlock: 2-8 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-44 [12, 256, 32, 32] (294,912)
│ │ └─BatchNorm2d: 3-45 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-46 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-47 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-48 [12, 256, 32, 32] (512)
│ │ └─Sequential: 3-49 [12, 256, 32, 32] (33,280)
│ │ └─ReLU: 3-50 [12, 256, 32, 32] --
│ └─BasicBlock: 2-9 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-51 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-52 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-53 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-54 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-55 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-56 [12, 256, 32, 32] --
│ └─BasicBlock: 2-10 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-57 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-58 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-59 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-60 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-61 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-62 [12, 256, 32, 32] --
│ └─BasicBlock: 2-11 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-63 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-64 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-65 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-66 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-67 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-68 [12, 256, 32, 32] --
│ └─BasicBlock: 2-12 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-69 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-70 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-71 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-72 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-73 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-74 [12, 256, 32, 32] --
│ └─BasicBlock: 2-13 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-75 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-76 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-77 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-78 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-79 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-80 [12, 256, 32, 32] --
├─Sequential: 1-8 [12, 512, 16, 16] --
│ └─BasicBlock: 2-14 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-81 [12, 512, 16, 16] (1,179,648)
│ │ └─BatchNorm2d: 3-82 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-83 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-84 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-85 [12, 512, 16, 16] (1,024)
│ │ └─Sequential: 3-86 [12, 512, 16, 16] (132,096)
│ │ └─ReLU: 3-87 [12, 512, 16, 16] --
│ └─BasicBlock: 2-15 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-88 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-89 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-90 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-91 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-92 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-93 [12, 512, 16, 16] --
│ └─BasicBlock: 2-16 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-94 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-95 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-96 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-97 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-98 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-99 [12, 512, 16, 16] --
├─AdaptiveAvgPool2d: 1-9 [12, 512, 1, 1] --
├─Linear: 1-10 [12, 5] 2,565
==========================================================================================
Total params: 21,280,965
Trainable params: 5,829
Non-trainable params: 21,275,136
Total mult-adds (G): 224.73
==========================================================================================
Input size (MB): 12.58
Forward/backward pass size (MB): 3749.71
Params size (MB): 85.12
Estimated Total Size (MB): 3847.42
==========================================================================================
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [12, 5] --
├─Conv2d: 1-1 [12, 64, 256, 256] 3,136
├─BatchNorm2d: 1-2 [12, 64, 256, 256] 128
├─ReLU: 1-3 [12, 64, 256, 256] --
├─MaxPool2d: 1-4 [12, 64, 128, 128] --
├─Sequential: 1-5 [12, 64, 128, 128] --
│ └─BasicBlock: 2-1 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-1 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-2 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-3 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-4 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-5 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-6 [12, 64, 128, 128] --
│ └─BasicBlock: 2-2 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-7 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-8 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-9 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-10 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-11 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-12 [12, 64, 128, 128] --
│ └─BasicBlock: 2-3 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-13 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-14 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-15 [12, 64, 128, 128] --
│ │ └─Conv2d: 3-16 [12, 64, 128, 128] (36,864)
│ │ └─BatchNorm2d: 3-17 [12, 64, 128, 128] (128)
│ │ └─ReLU: 3-18 [12, 64, 128, 128] --
├─Sequential: 1-6 [12, 128, 64, 64] --
│ └─BasicBlock: 2-4 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-19 [12, 128, 64, 64] (73,728)
│ │ └─BatchNorm2d: 3-20 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-21 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-22 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-23 [12, 128, 64, 64] (256)
│ │ └─Sequential: 3-24 [12, 128, 64, 64] (8,448)
│ │ └─ReLU: 3-25 [12, 128, 64, 64] --
│ └─BasicBlock: 2-5 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-26 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-27 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-28 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-29 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-30 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-31 [12, 128, 64, 64] --
│ └─BasicBlock: 2-6 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-32 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-33 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-34 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-35 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-36 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-37 [12, 128, 64, 64] --
│ └─BasicBlock: 2-7 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-38 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-39 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-40 [12, 128, 64, 64] --
│ │ └─Conv2d: 3-41 [12, 128, 64, 64] (147,456)
│ │ └─BatchNorm2d: 3-42 [12, 128, 64, 64] (256)
│ │ └─ReLU: 3-43 [12, 128, 64, 64] --
├─Sequential: 1-7 [12, 256, 32, 32] --
│ └─BasicBlock: 2-8 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-44 [12, 256, 32, 32] (294,912)
│ │ └─BatchNorm2d: 3-45 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-46 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-47 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-48 [12, 256, 32, 32] (512)
│ │ └─Sequential: 3-49 [12, 256, 32, 32] (33,280)
│ │ └─ReLU: 3-50 [12, 256, 32, 32] --
│ └─BasicBlock: 2-9 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-51 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-52 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-53 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-54 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-55 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-56 [12, 256, 32, 32] --
│ └─BasicBlock: 2-10 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-57 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-58 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-59 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-60 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-61 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-62 [12, 256, 32, 32] --
│ └─BasicBlock: 2-11 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-63 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-64 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-65 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-66 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-67 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-68 [12, 256, 32, 32] --
│ └─BasicBlock: 2-12 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-69 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-70 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-71 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-72 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-73 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-74 [12, 256, 32, 32] --
│ └─BasicBlock: 2-13 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-75 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-76 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-77 [12, 256, 32, 32] --
│ │ └─Conv2d: 3-78 [12, 256, 32, 32] (589,824)
│ │ └─BatchNorm2d: 3-79 [12, 256, 32, 32] (512)
│ │ └─ReLU: 3-80 [12, 256, 32, 32] --
├─Sequential: 1-8 [12, 512, 16, 16] --
│ └─BasicBlock: 2-14 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-81 [12, 512, 16, 16] (1,179,648)
│ │ └─BatchNorm2d: 3-82 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-83 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-84 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-85 [12, 512, 16, 16] (1,024)
│ │ └─Sequential: 3-86 [12, 512, 16, 16] (132,096)
│ │ └─ReLU: 3-87 [12, 512, 16, 16] --
│ └─BasicBlock: 2-15 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-88 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-89 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-90 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-91 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-92 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-93 [12, 512, 16, 16] --
│ └─BasicBlock: 2-16 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-94 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-95 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-96 [12, 512, 16, 16] --
│ │ └─Conv2d: 3-97 [12, 512, 16, 16] (2,359,296)
│ │ └─BatchNorm2d: 3-98 [12, 512, 16, 16] (1,024)
│ │ └─ReLU: 3-99 [12, 512, 16, 16] --
├─AdaptiveAvgPool2d: 1-9 [12, 512, 1, 1] --
├─Linear: 1-10 [12, 5] 2,565
==========================================================================================
Total params: 21,280,965
Trainable params: 5,829
Non-trainable params: 21,275,136
Total mult-adds (G): 224.73
==========================================================================================
Input size (MB): 12.58
Forward/backward pass size (MB): 3749.71
Params size (MB): 85.12
Estimated Total Size (MB): 3847.42
==========================================================================================Predict Using a Pretrained Model
Let’s now use a pre-trained network to predict the label for an input image. Here, I will use a picture of my cat Peri. The path to the file is defined and the image is read in using PIL. I then plot the image using imshow() from matplotlib.
imgPth = "data/files/peri.jpg"img1 = Image.open(imgPth)plt.imshow(img1)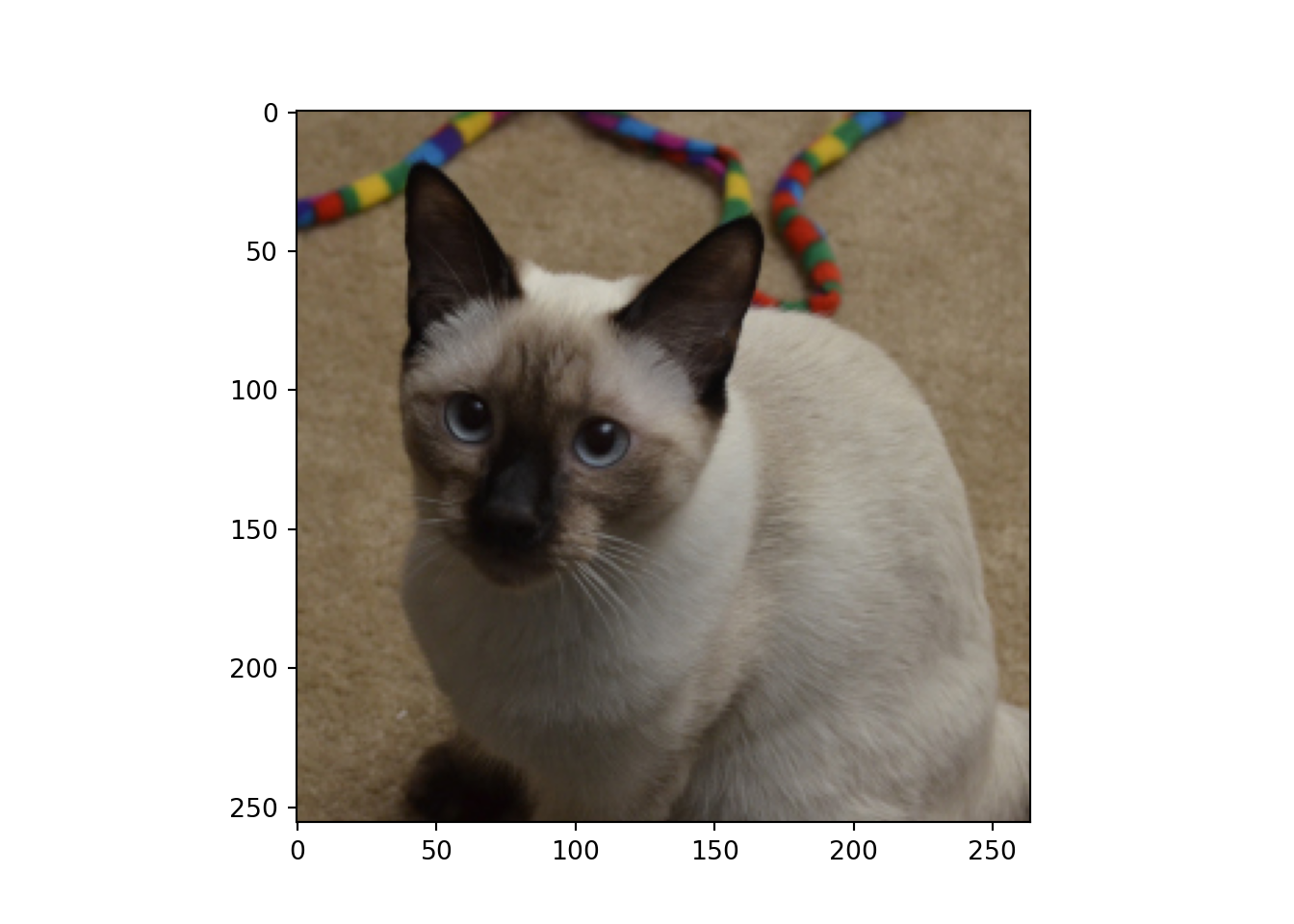
Since I will use a pre-trained model and not make any modifications to the architecture, as I did above, the image will need to be transformed to the anticipated shape. This is accomplished using transforms as define by torchvision. I also normalize the bands relative to the band means and standard deviations of ImageNet, the dataset used to develop the pre-trained weights being used. This is generally required when using pre-trained weights.
I then apply the defined transforms to the image, which includes transforming it to a torch tensor. The unsqueeze() function is used to add a dimension at index 0 since the model expects a batch dimension. The image is then moved to the device.
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])imgT = transform(img1)
imgB = torch.unsqueeze(imgT, 0).to(device)I instantiate an instance of a ResNet-34 model with pre-trained weights and move it to the device.
model = torchvision.models.resnet34(pretrained=True).to(device)The model is also placed in evaluation mode using the eval() method for the model. This is important so that using the model does not impact the computational graph or gradients. I next predict the image using the model.
I read in a mapping of the class codes and associated class labels that was obtained at the commented out link. ImageNet differentiates a total of 1,000 classes. Using the results and this mapping, I then print the class with the highest predicted probability followed by the top 5 classes.
The model predicted that the image was of a “Siamese cat” with a 99.8% probability. This is pretty impressive. The next two highest rankings are two other types of cats followed by “paper towel” and “sleeping bag”.
model.eval()ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)prediction = model(imgB)#https://learnopencv.com/pytorch-for-beginners-image-classification-using-pre-trained-models/
with open('data/files/imagenet1000_clsidx_to_labels.txt') as f:
classes = [line.strip() for line in f.readlines()]_, index = torch.max(prediction, 1)
percentage = torch.nn.functional.softmax(prediction, dim=1)[0] * 100
print(classes[index[0]], percentage[index[0]].item())284: 'Siamese cat, Siamese', 99.83098602294922_, indices = torch.sort(prediction, descending=True)
[(classes[idx], percentage[idx].item()) for idx in indices[0][:5]][("284: 'Siamese cat, Siamese',", 99.83098602294922), ("287: 'lynx, catamount',", 0.04350800812244415), ("285: 'Egyptian cat',", 0.03190483897924423), ("700: 'paper towel',", 0.006886311341077089), ("797: 'sleeping bag',", 0.006694042589515448)]Display Feature Maps
The next set of code was obtained from the following Medium post:
https://ravivaishnav20.medium.com/visualizing-feature-maps-using-pytorch-12a48cd1e573
The goal of this code is to generate visualizations of the feature maps. Remember that feature maps represent the learned kernels applied to the input data or prior feature maps from the prior layers. We will specifically make use of the results from the ResNet-32 model applied to the picture of Peri that were obtained above.
This code does the following:
- Extract and store all of the nn.Conv2d() layers in a list and all of the associated kernel weights in a second list
- Apply the kernels to the input image to obtain feature maps and save the outputs and associated names to lists
- Sum across channels
- Generate a plot of learned feature maps
It is interesting to explore the learned feature maps to determine what features of the image are being used to make predictions at the varying levels of the architecture. It is also interesting to see the impact of max pooling on the spatial dimensions of the array.
I encourage you to read the Medium post referenced here for a more detailed discussion of this code.
#https://ravivaishnav20.medium.com/visualizing-feature-maps-using-pytorch-12a48cd1e573
# we will save the conv layer weights in this list
model_weights =[]
#we will save the 49 conv layers in this list
conv_layers = []
# get all the model children as list
model_children = list(model.children())
#counter to keep count of the conv layers
counter = 0
#append all the conv layers and their respective wights to the list
for i in range(len(model_children)):
if type(model_children[i]) == nn.Conv2d:
counter+=1
model_weights.append(model_children[i].weight)
conv_layers.append(model_children[i])
elif type(model_children[i]) == nn.Sequential:
for j in range(len(model_children[i])):
for child in model_children[i][j].children():
if type(child) == nn.Conv2d:
counter+=1
model_weights.append(child.weight)
conv_layers.append(child)
print(f"Total convolution layers: {counter}")Total convolution layers: 33print("conv_layers")conv_layersimage = imgBoutputs = []
names = []
for layer in conv_layers[0:]:
image = layer(image)
outputs.append(image)
names.append(str(layer))
print(len(outputs))
#print feature_maps33for feature_map in outputs:
print(feature_map.shape)torch.Size([1, 64, 112, 112])
torch.Size([1, 64, 112, 112])
torch.Size([1, 64, 112, 112])
torch.Size([1, 64, 112, 112])
torch.Size([1, 64, 112, 112])
torch.Size([1, 64, 112, 112])
torch.Size([1, 64, 112, 112])
torch.Size([1, 128, 56, 56])
torch.Size([1, 128, 56, 56])
torch.Size([1, 128, 56, 56])
torch.Size([1, 128, 56, 56])
torch.Size([1, 128, 56, 56])
torch.Size([1, 128, 56, 56])
torch.Size([1, 128, 56, 56])
torch.Size([1, 128, 56, 56])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 512, 14, 14])
torch.Size([1, 512, 14, 14])
torch.Size([1, 512, 14, 14])
torch.Size([1, 512, 14, 14])
torch.Size([1, 512, 14, 14])
torch.Size([1, 512, 14, 14])processed = []
for feature_map in outputs:
feature_map = feature_map.squeeze(0)
gray_scale = torch.sum(feature_map,0)
gray_scale = gray_scale / feature_map.shape[0]
processed.append(gray_scale.data.cpu().numpy())
for fm in processed:
print(fm.shape)(112, 112)
(112, 112)
(112, 112)
(112, 112)
(112, 112)
(112, 112)
(112, 112)
(56, 56)
(56, 56)
(56, 56)
(56, 56)
(56, 56)
(56, 56)
(56, 56)
(56, 56)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(28, 28)
(14, 14)
(14, 14)
(14, 14)
(14, 14)
(14, 14)
(14, 14)fig = plt.figure(figsize=(30, 50))
for i in range(len(processed)):
a = fig.add_subplot(10, 4, i+1)
imgplot = plt.imshow(processed[i])
a.axis("off")
a.set_title(names[i].split('(')[0], fontsize=30)(-0.5, 111.5, 111.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 111.5, 111.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 111.5, 111.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 111.5, 111.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 111.5, 111.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 111.5, 111.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 111.5, 111.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 55.5, 55.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 55.5, 55.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 55.5, 55.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 55.5, 55.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 55.5, 55.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 55.5, 55.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 55.5, 55.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 55.5, 55.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 27.5, 27.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 13.5, 13.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 13.5, 13.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 13.5, 13.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 13.5, 13.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 13.5, 13.5, -0.5)
Text(0.5, 1.0, 'Conv2d')
(-0.5, 13.5, 13.5, -0.5)
Text(0.5, 1.0, 'Conv2d')plt.show(fig)
Concluding Remarks
We are now ready to move on to the last section focused on using CNNs for scene labeling tasks. In this section, we will combine what was discussed and demonstrated in the prior CNN modules to train a scene classification model using transfer learning and a modified ResNet-34 architecture.